Django High Performance
Nosotros en Alluxi tenemos muy en cuenta que el performace de un sistema importa y como una de nuestras principales herramienta de trabajo es el framework Django queremos compartir en este post algunos puntos bastante interesantes de un libro llamado: High Performance Django by Peter Baumgartner es un poco viejo; exactamente del año 2014, aún así, como mencionábamos trae unos puntos muy interesantes que revisaremos a continuación.
Cuando hablamos de simplicidad nos referimos a:
- Usar la menor cantidad posible de piezas móviles para que todo funcione. Las “partes móviles” pueden ser servidores, servicios o software de terceros.
- Elegir partes móviles probadas y confiables en lugar del nuevo hotness.
- Usar una arquitectura probada y confiable en lugar de abrir tu propio camino.
- Desvíe el tráfico de las partes complejas hacia partes simples, escalables y rápidas.
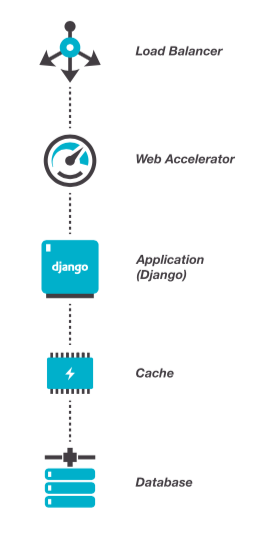
Algunas de las herramientas mas comunes son:
Load Balancer: Es un equilibrador de carga, cuya principal responsabilidad es enviar el tráfico a su infraestructura subyacente. Actúa como un único punto proxy que recibe solicitudes de Internet y las envía a servidores de aplicaciones en buen estado.
Como ejemplo tenemos:
- Open Source: HAProxy, Nginx, Varnish
- Commercial: Amazon ELB (Elastic Load Balancer), Rackspace Clould Load Balancer
Web Accelerator: El acelerador web (también conocido como caché de proxy inverso HTTP) es la primera línea de defensa para los servidores de aplicaciones que se encuentran más abajo en la pila (imagen de arriba)
Algunos pueden ser:
- Open Source: Varnish, Nginx + Memcached
- Commercial: Fastly, Cloudflare
App Server: El servidor de aplicaciones tiene una tarea sencilla: convierte su solicitud HTTP en una solicitud WSGI (interfaz de puerta de enlace del servidor web) que Python puede entender, el preferido es uWSGI
Database: Postgres, MySQL/MariaDB
Hay muchos lugares en donde se puede optimizar Django y es fácil caer en la trampa de optimizar cosas que no se necesitan. Si tenemos la tarea de optimizar un sitio ya existente debemos analizar cuales son los puntos más calientes y optimizarlos.
El desarrollo
Entorno Local
Es muy importante hacer un entorno que sea fácilmente instalable acelerará la incorporación de nuevos desarrolladores y ayudará a contrarrestar la complejidad innecesaria.
El entorno de desarrollo local deberá ser lo más cerca posible al de la producción. Ejemplo: Si se usa Postgres en los servidores de producción no usar SQLite localmente
Settings
Lo ideal es crear un módulo de configuración, originalmente solo tendrá un único archivo de configuración; y a medida de que el proyecto se vuelve suficientemente grande, el enfoque tienen a ser un poco realista, en lugar de un archivo creamos algunos submódulos:
- settings.base: La configuración compartida entre los deploys, este debería ser el archivo más grande del grupo
- settings.dev: Configuraciones comunes para que el proyecto se ejecute localmente, reemplazando cualquier servicio que no pueda ejecutarse localmente y habilitar la depuración
- settings.deploy: Algunos tweeks para la implementación, como la implementación de las capas de caché
Y todas las configuraciones se heredan de settings.base algo así:
from myproject.settings.base import *Para datos sensibles como: SECRET_KEY, APIS, ubicación de base de datos y credenciales debemos usar un .env
SECRET_KEY=abdefg12345hijklmno
DATABASE_URL=postgres://u:pw@dbhost:5432/db_nameEste enfoque incluirá las variables en sus procesos web pero no estarán disponibles para ejecutar comandos de administración. Para ese caso podemos hacer uso de un export desde el bash.
Hay que tener mucho cuidado con el uso de las librerías de terceros, siempre debemos evaluar los módulos de terceros antes de integrarlos al proyecto, para ellos podemos hacernos preguntas, como por ejemplo:
- ¿Cubre sus requisitos exactos o simplemente se acerca?
- ¿Es saludable para el proyecto?
- ¿El manteiner tiene buen historial?
- ¿Está bien documentado?
- ¿Tiene buena cobertura de pruebas?
- ¿Como es la comunidad? ¿Tiene desarrrollo activo?
- ¿Tiene una gran cantidad de issues o pull request?
- ¿Como es el performance?
- ¿Realiza muchas peticiones a la base de datos?
- ¿Tiene algún impacto en el resto de sus aplicaciones?
- ¿Tiene licencia y es compatible con su proyecto?
Las aplicaciones de terceros no mantenidas se convertirán rápidamente en un responsabilidad para su proyecto.
Vigilando el rendimiento
Django Debug Tool Bar es la herramienta elegida para este trabajo. Nos proporciona entre otras cosas: información de consultas de base de datos, templates usadas y tiempos de carga.
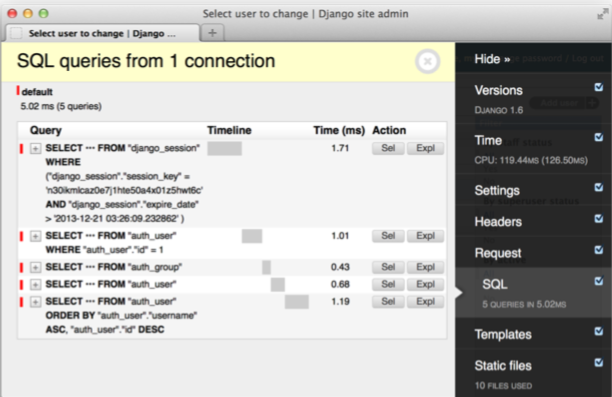
Uno de los detalles de Django Debug Tool Bar es que no funciona para consultas Ajax para ese caso podemos usar: django-debug-panel
Para optimizar el código de manera eficiente se deberá hacerse estas preguntas:
- ¿Cuántas consultas SQL se ejecutaron?
- ¿Cuál fue el tiempo acumulado en la base de datos?
- ¿Qué consultas individuales se ejecutaron y cuánto tiempo tomó cada una?
- ¿Qué código genera cada consulta?
- ¿Qué plantillas se usaron para renderizar la página?
- ¿Cómo afecta el caché al rendimiento?
DONDE OPTIMIZAR
En casi todas las aplicaciones web dinámicas el cuello de botella siempre es la base de datos ya que con frecuencia necesita acceder a la información de los discos y realiza cálculos costosos en la memoria para consultas complejas.
Minimizar el número de consultas como el tiempo que necesitan para ejecutarse es una forma segura de acelerar su aplicación.
REDUCIR EL NÚMERO DE QUERIES
El ORM de Django hacer que sea trivial consultar y recuperar información de la base de datos. Un efecto secundario es que genera muchas consultas.
Una buena práctica es usar select_related y prefetch_related, estos queryset son útiles cuando se sabe que haremos consultas con un foreign_key
# una consulta a la tabla post
post = Post.objects.get(slug='this-post')
# una consulta a la tabla autor
name = post.author.nameEl anterior código hace dos consultas a la base de datos; uno para buscar la publicación y otro para buscar al autor.
Un select_related puede reducir a la mitad las consultas:
post = (Post.objects.select_related('author').get(slug='this-post'))Las consultas se acumulan por ejemplo:
post_list = Post.objects.all()
# Template
{% for post in post_list %}
{{ post.title }} By {{ post.author.name }} in {{ post.category.name}}
{% endfor %}Ese código hará dos consultas en cada iteración [autor y categoría], en una lista de 20 post podemos reducir de 41 a 1 usando select_related
post_list = (Post.objects.all().select_related('author','category'))Eso hará JOINS para buscar los datos necesarios en una sola consulta.
select_related tiene un método complementario prefetch_related que permitirá hacer búsquedas en la otra dirección (obtener todos los padres para cada hijo determinado) aquí tienes un ejemplo del funcionamiento
REDUCIR EL TIEMPO DE LAS CONSULTAS
Podemos checar el tiempo de consultas usando Django Debug Tool Bar, cuando una consulta toma más de 50 ms puede considerarse como lenta, hay que verificar los siguientes problemas:
Índices Faltantes: cuando trabajamos con datos locales nunca veremos el problema porque nuestro RDBMS puede escanear la tabla rápidamente, esta es una buena razón para probar con datos que se aproximan a lo que tiene producción.
El lugar principal donde un índice faltante afectará el rendimiento es cuando la cláusula WHERE se usa en una columna no indexada en una tabla grande. Explicación de los indices y un ejemplo de como indexar modelos
JOINS
Si notamos una consulta lenta con una cláusula JOIN grande, tratemos de ver si podemos reescribirla, para hacer menos combinaciones. En algunos casos, dos consultas pueden realizar mucho mejor que una; puede obtener los ID de la primera consulta y pasarlos a la segunda consulta:
tag_ids = (Post.objects.all().values_list('id', flat=True).distinct())
tags = Tag.objects.filter(id__in=tag_ids)MUCHOS RESULTADOS
Hay que tener cuidado de no hacer consultas ilimitadas, es fácil hacer un .all() que va a funcionar muy bien en nuestra entorno de desarrollo, pero en producción devuelve miles de resultados, hay que limitar las consultas utilizando querysets [:20] donde 20 es el máximo resultado devuelto o usar paginación cuando sea adecuado.
COUNTS
Los conteos de la base de datos son notoriamente lentos, hay que evitarlos cuando sea posible.
posts = Post.objects.all()
if posts.count() > 0:
# do somethingpodemos cambiarlo por esto:
posts = Post.objects.all()
if posts.exists():
# do somethingMÉTODOS CAROS EN MODELOS
Una práctica común de MVC es tener “fat models” que tengan métodos para las propiedades de uso frecuente en un objeto.
A menudo estos métodos realizan una serie de consultas a la base de datos y las agrupan como una propiedad única que es conveniente para su reutilización en otros lugares. Si se accede a las propiedades más de una vez por solicitud, podemos optimizarla con la memorización. Lo bueno de esta técnica es que la memoria caché solo dura en el ciclo solicitud/respuesta por lo que está protegido de los problemas con los datos que se vuelven obsoletos.
from django.utils.functional import cached_property
class TheModel(models.Model):
…
@cached_property
def expensive(self):
# expensive computation of result return resultRESULTADOS MUY LARGOS
Si sus modelos tienen campos que almacenan cantidades de datos suficientemente grandes, podría estar desacelerando la transferencia Django proporciona algunos métodos queryset para solucionar esto defer y only devuelve los objetos del modelo mientras que values y values_list devuelven una lista de diccionarios y tuplas, respectivamente.
# retrieve everything but the `body` field
posts = Post.objects.all().defer('body')
# retrieve only the `title` field
posts = Post.objects.all().only('title')
# retrieve a list of {'id': id} dictionaries
posts = Post.objects.all().values('id')
# retrieve a list of (id,) tuples
posts = Post.objects.all().values_list('id')
# retrieve a list of ids
posts = Post.objects.all().values_list('id', flat=True)CACHING EN QUERYS
El siguiente lugar para buscar ganancias de rendimiento es eliminar las consultas duplicadas a través del almacenamiento en caché. Una caché de consulta se ubica efectivamente entre el ORM y la base de datos almacenando, recuperando e invalidando su caché automáticamente.
Hay una buena opción para el usar el caché es Johnny Cache Johnny Cache trabaja a través de un middleware personalizado. Este middleware captura las solicitudes y coloca los resultados de cualquier lectura de base de datos en el caché (Memcached o Redis). Las solicitudes futuras buscarán las consultas almacenadas en el caché y las utilizarán en lugar de llegar a la base de datos. Esas consultas se almacenan en caché para siempre y la invalidación basada en clave se utiliza para mantenerla actualizada, si Johnny Cache intercepta una escritura en una tabla específica, actualiza una clave que invalida todas las consultas en caché para esa tabla.
RAW QUERIES
El ORM de Django es flexible, pero no puede hacer todo. A veces, pasar al SQL sin formato puede ayudarlo a aplicar una consulta de bajo rendimiento en una que sea más eficaz.
ALTERNATIVAS PARA EL ALMACENAMIENTO DE DATOS
Existen escenarios en los que una base de datos alternativa puede complementar un RDBMS que actúa como almacenamiento principal. El ejemplo más común de esto es enviar datos a Elasticicsearch o Solr para sus capacidades de búsqueda de texto completo.
Otra base de datos NoSQL que encontrarás escondida detrás de muchos sitios de alto rendimiento es Redis. No solo es increíblemente rápido, sino que también ofrece algunas estructuras de datos únicas que pueden aprovecharse para hacer cosas difíciles o costosas en un RDBMS.
OPTIMIZACIÓN DE TEMPLATES
Usar {% block %} es más rápido que usar {% include %}
Las plantillas muy fragmentadas, ensambladas a partir de muchas piezas pequeñas, pueden afectar el rendimiento
Usar la técnica de las muñecas rusas que es básicamente, anidar llamadas de caché con diferentes vencimientos. Dado que la plantilla completa no caducará simultáneamente, solo se deben procesar los bits y las piezas en cualquier solicitud determinada.
{% cache MIDDLE_TTL "post_list" request.GET.page %}
{% include "inc/post/header.html" %}
<div class="post-list">
{% for post in post_list %}
{% cache LONG_TTL "post_teaser_" post.id post.last_modified %}
{% include "inc/post/teaser.html" %}
{% endcache %}
{% endfor %}
</div>
{% endcache %}MIDDLE_TTL y LONG_TTL son variables. Predefinimos algunos valores de tiempo de espera de caché en la configuración y los pasamos a las plantillas a través de un procesador de contexto.
Esto nos permite ajustar el comportamiento del almacenamiento en caché en todo el sitio desde una ubicación central. Si no está seguro de por dónde empezar, estamos contentos con 10 minutos (cortos), 30 minutos (medianos), una hora (largos) y 7 días (para siempre) en sitios con mucha lectura y contenido.
COLAS DE TRABAJO (Job Queue)
Las aplicaciones web modernas comúnmente tienen vistas que necesitan hacer llamadas a servicios externos o realizar un procesamiento pesado de datos o archivos, la mejor manera de hacer que esas vistas sean rápidas es empujar el trabajo lento a una cola de trabajos.
En Python Celery es la cola de trabajo elegida.
Para volúmenes bajos, Redis es lo suficientemente bueno para actuar como un servicio de cola y, si ya está en uso, ayuda a mantener su infraestructura simple.
Los buenos candidatos para enviar tareas al background son:
- Llamadas a APIS de terceros
- Enviar emails
- Tareas de cómputo pesadas (procesamiento de video, procesamiento de números, etc.)
Mantenga sus tareas pequeñas y no dude en tener una tarea que genere más tareas. Al dividir los trabajos de larga duración en pequeñas tareas atómicas, puede distribuirlos entre más workers / CPU y agitarlos más rápido.
Acerca de las tareas programadas son buenos candidatos para los informes de administración, la limpieza de registros muertos en la base de datos o la obtención de datos de servicios de terceros
OPTIMIZAR EL FRONTEND
De alguna manera, puede pensar en los archivos CSS y JavaScript como consultas de base de datos:
• Menos es mejor.
• Cuanto más pequeño es mejor.
• Deben ser almacenados en caché siempre que sea posible
Podemos usar herramientas para comprimir nuestros archivos css y js como es: django-pipeline
COMPRIMIR IMAGENES
Los archivos estáticos son suficientemente fácil de optimizar usando pngcrush.
Si el usuario subirá sus imágenes podemos usar easy-thumbnails o django versatilefiled
SERVIR ARCHIVOS DESDE UN CDN
Aprovechar una CDN como las que proporcionan Amazon Cloudfront o Rackspace / Akamai no solo mejorará el rendimiento para sus usuarios finales, sino que también reducirá el tráfico y la complejidad de sus servidores. Al colocar estos activos en una CDN, puede permitir que sus servidores se centren en el servicio de datos dinámicos y dejar archivos estáticos a su CDN.
CARGA DE ARCHIVOS
Las ofertas comerciales como Amazon S3 o Rackspace Cloud Files serán opciones más fáciles y relativamente económicas, como beneficio adicional, podrás usar su CDN como parte del paquete.
PRUEBAS AUTOMÁTICAS E INTEGRACIÓN CONTINUA
Al principio de su proceso de desarrollo, debe tener implementado un sistema de integración continua que ejecutará pruebas automatizadas y controles de estado en su base de código para garantizar que esté en buenas condiciones.
Podemos usar Jenkins CI para ejecutar una serie de verificaciones en nuestro código, que incluyen:
• Pruebas unitarias.
• Cobertura de código
• PEP8 / Linting
• Pruebas funcionales vía Selenium.
• Pruebas de rendimiento a través de Jmeter
DEPLOYMENT
Para el despliegue generalmente se ocupan sistemas basados en Linux el más popular es Ubuntu ya que es la distribución preferida entre los desarrolladores de Django.
MANEJO DE PROCESOS
Hay muchas opciones para asegurarse de que sus servicios se inicien cuando el servidor se inicie y se reinicien en caso de una falla, es preferible usar las herramientas predeterminadas del sistema operativo (upstart, systemd, etc.) en lugar de agregar otra capa de software.
MÚLTIPLES AMBIENTES REMOTOS
La cantidad de entornos que tiene depende de su flujo de trabajo, pero se tiene que planear tener al menos dos (puesta en escena / desarrollo y producción).
Puede escalar horizontalmente (menos servidores) y verticalmente (menos recursos por servidor), pero intente mantener el mismo diseño general de servidor / servicio.
Cada entorno separado debe estar completamente aislado de los demás, especialmente producción. Su equipo debe tener confianza en que puede romper las cosas en el desarrollo sin tener que retirar los servicios de producción.
Cada entorno debe estar lo más cerca posible de la producción (configuración, software, sistema operativo, etc.) Hay pocas cosas más enloquecedoras para un desarrollador que un error que solo aparece en producción debido a la falta de paridad en el entorno de desarrollo.
En su esfuerzo por alcanzar la paridad del entorno, llegará a lugares donde entra en conflicto con el objetivo de aislamiento del entorno.
EVITANDO PUNTOS DE FALLA INDIVIDUALES
Se tiene que hacer copias de seguridad de los datos ya que perderlos puede ser catastrófico, podemos crear scritps que hagan copias periódicamente de la base de datos
Esperemos que este pequeño articulo haya servido para describir nuevas herramientas e incorporarlas en nuestro flujo de trabajo cuando creemos software.
Happy Coding.